# 什么是数据湖?及其架构
声明:本文原文为:What is Data Lake? It's Architecture (opens new window),图片源自原文,译者@Jacen,转载请注明。
# 什么是数据湖?
数据湖(Data Lake)是可以存储大量结构化、半结构化和非结构化数据的存储仓库。它是一个以其原生格式存储每种类型数据的场所,对帐户大小或文件没有固定限制。它提供大量数据,以提高分析性能和原生集成。
数据湖就像一个大容器,与真实的湖泊和河流非常相似。就像在湖中有多个支流进入一样,数据湖具有结构化数据,非结构化数据,机器对机器,实时流经的日志。
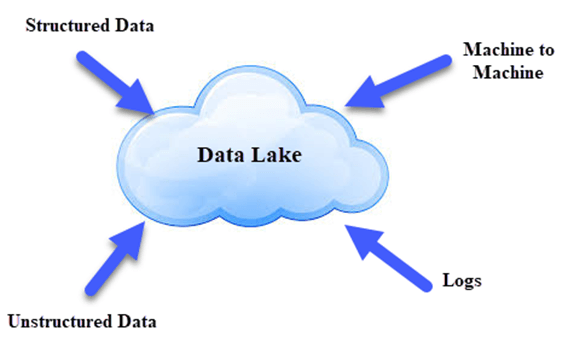
数据湖使数据更易处理,是一种经济高效的方式来存储组织的所有数据以供以后处理。数据分析师可以专注于发现数据中的有意义的模式,而不是数据本身。
与将数据存储在文件和文件夹中的分层数据仓库不同,Data lake具有扁平的体系结构。数据湖中的每个数据元素都有一个唯一的标识符,并用一组元数据信息进行标记。
# 为什么需要使用数据湖?
建立数据湖的主要目的是向数据科学家提供未完善的数据视图。
使用数据湖的理由如下:
- 随着诸如Hadoop之类的存储引擎的兴起,存储不同的信息变得十分容易。无需使用数据湖将数据建模到企业范围的架构中。
- 随着数据量、数据质量以及元数据的增加,分析的质量也随之提高。
- 数据湖提供业务敏捷性
- 机器学习和人工智能可用于做出有收益的预测。
- 它为组织提供了竞争优势。
- 没有数据筒仓结构。数据湖提供了全面的客户视图,并使分析更加强大。
# 数据湖的架构
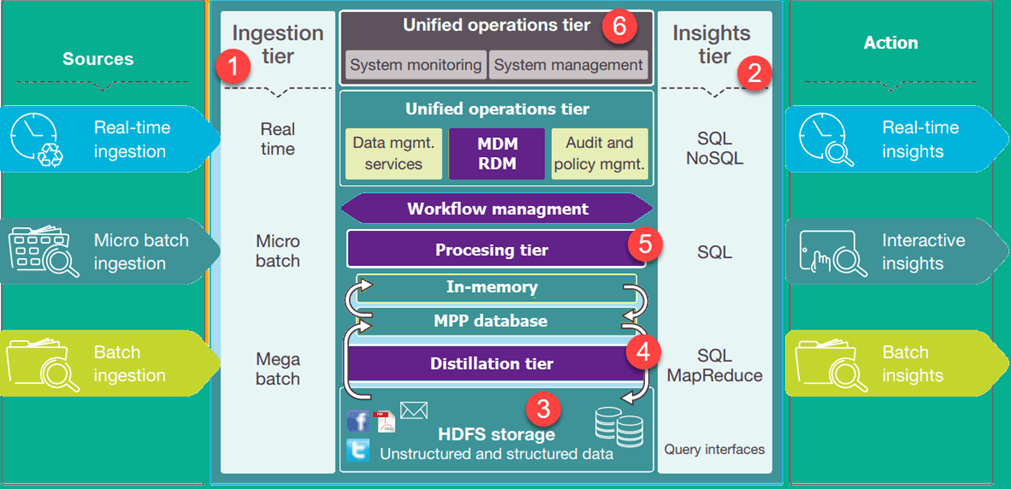
本图展示了一个业务数据湖的架构。较低的级别表示大多数情况下处于空闲状态的数据,而较高的级别表示实时事务数据。数据流经系统时,无延时或者几乎无延时。以下是数据湖架构中重要的层:
1、提取层:左侧的层描述了数据源。数据可以批量或者实时加载到数据湖中。
2、洞察层:右侧的层代表使用系统洞察力的分析方。SQL、NoSQL查询,甚至excel都可以用于数据分析。
3、HDFS:是针对结构化和非结构化数据的低成本解决方案。它是系统中所有静止数据的着陆区。
4、蒸馏层:从存储层中获取数据,并将其转为为结构化数据,以便分析。
5、处理层:以不同的实时、交互式、批处理方式运行分析算法和用户查询,以生成便于分析的结构化数据。
6、统一层:控制系统管理和监控。它包括审计和熟练度管理、数据管理、工作流管理。
# 关键的数据湖概念
以下是人们需要了解的关键的数据湖概念,以完全理解数据湖架构。
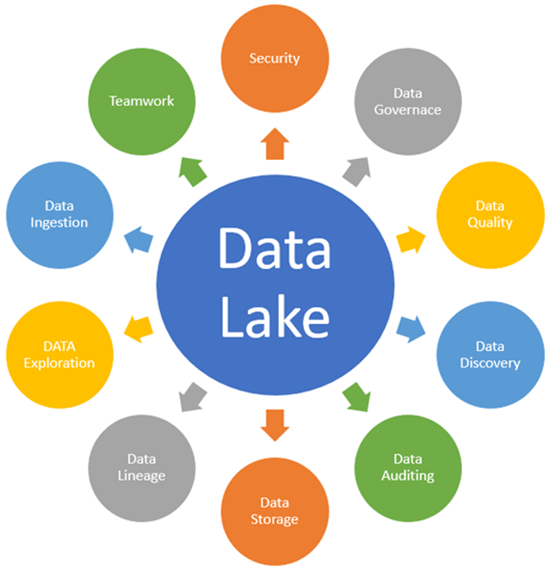
数据提取
数据提取允许连接器从其他数据源获取数据并将其加载到数据湖中。
数据提取支持:
- 所有类型的结构化、半结构化和非结构化数据。
- 多种提取方式,如:批处理、实时、一次性加载。
- 多源数据,如:数据库、Web服务、电子邮件、物联网和FTP。
数据存储
数据存储应可扩展,提供了经济高效的存储,并允许快速的进行数据浏览。它需要支持多种类型的数据格式。
数据治理
数据治理是管理组织中使用的数据的可用性、安全性和完整性的过程。
安全
安全性需要在数据湖的每一层实现。它从存储、发掘和消费开始。基本需要是停止未经授权的用户访问。它应支持使用易于浏览的GUI和仪表盘访问数据的各种工具。身份验证、计费、授权和数据保护是数据湖安全的一些重要特性。
数据质量
数据质量是数据湖架构的重要组成部分。数据被用于提取商业价值。从质量差的数据中洞察会导致低质量的洞察结果。
数据发现
在开始准备数据或分析之前,数据发现是另一个重要阶段。在此阶段,通过组织和解释被提取到数据湖中的数据,使用标记技术来表达对数据的理解。
数据审计
两个主要的数据审计任务是跟踪对关键数据集的更改。
1、跟踪重要数据集元素的更改
2、捕获如何/何时/以及谁对这些元素进行更改。
数据审计有助于评估风险和合规性。
数据沿袭
这部分处理数据的来源。它主要处理随着时间变迁它移动到了那里以及发生了什么。它简化了数据分析过程中从起点到终点的错误纠正。
数据探索
它是数据分析的开始阶段。在启动数据探索之前,它有助于识别正确的数据集。
所有给定的组件需要协同工作,以便在数据湖构建中发挥重要作用,轻松的演进和探索环境。
# 数据湖的成熟阶段
不同教材对数据湖成熟度阶段的定义不同。虽然问题的症结仍然存在。成熟之后,阶段的定义是从外行的角度定义的。

阶段1:大规模处理和提取数据
数据湖成熟第一阶段包括提高转换和分析数据的能力。在这里,企业主需要根据他们的技能来寻找工具,以获取更多的数据并构建分析应用程序。
阶段2:建立分析能力
这是第二阶段,涉及到提高转换和分析数据的能力。在此阶段,公司将使用最适合其技能的工具。他们开始获取更多的数据并构建应用程序。在这里,企业数据仓库和数据湖一起使用。
阶段3:EDW和数据湖协同工作
这一步包括将数据和分析送到尽可能多的人手中。在此阶段,数据湖和企业数据仓库开始联合工作。两者都在分析中发挥作用。
阶段4:数据湖的企业级能力
在数据湖的成熟阶段,企业能力被添加到数据湖中。采用信息治理、信息声明周期管理和元数据管理。然而,很少有组织能够达到这种成熟水平,但是将来会增加。
# 数据湖最佳实践
体系结构组件、它们的交互以及确定性的产品应该支持本机数据类型
数据湖的设计应由可用而非所需驱动。直到被查询时,模式和数据需求时才被定义
设计应该被与服务API集成的一次性组件牵引
数据发掘、提取、存储、管理、质量、转换和可视化应该被独立管理。
数据湖架构应该对特定的行业进行定制。它应该确保该领域所需的功能是设计的固有部分
重要的是,更快的掌握新发现的数据源
数据湖有助于定制化管理,挖掘最大价值
数据湖应该支持现有的企业数据管理技术和方法
# 构建数据湖的挑战
- 在数据湖中,数据量较大,因此过程必须更加依赖于程序化管理
- 难以处理稀疏的、不完整的、易变的数据
- 更大范围的数据集和数据源需要更强大的数据治理和支持
# 数据湖和数据仓库的区别
| 参数 | 数据湖 | 数据仓库 |
|---|---|---|
| 数据 | 数据湖存储任何内容 | 数据仓库仅关注业务流程 |
| 处理 | 数据主要未经处理 | 高度处理的数据 |
| 数据类型 | 它可以是非结构化,半结构化和结构化的 | 它主要采用表格形式和结构 |
| 任务 | 共享数据管理 | 针对数据检索进行了优化 |
| 敏捷 | 高度敏捷,根据需要配置和重新配置 | 与数据湖相比,它不那么敏捷,并且具有固定的配置 |
| 用户 | 数据湖主要由数据科学家使用 | 业务专业人员广泛使用数据仓库 |
| 存储 | 数据湖用于低成本存储 | 使用了能够快速响应的昂贵存储 |
| 安全 | 提供较少的控制 | 更好地控制数据 |
| EDW更换 | 数据湖可以作为EDW的来源 | 与EDW互补(不可替代) |
| 模式 | 读时模式(无预定义模式) | 写时模式(预定义模式) |
| 数据处理 | 帮助快速提取新数据 | 耗时 |
| 数据粒度 | 粒度较低 | 详细 |
| 工具 | 可以使用像Hadoop / Map Reduce这样的开源/工具 | 主要是商业工具 |
# 使用数据湖的好处和风险
使用数据湖的主要好处如下:
- 充分帮助产品化和高级分析
- 提供经济高效的可扩展性和灵活性
- 从无限的数据类型中提供价值
- 降低长期持有成本
- 允许经济的存储文件
- 快速的适应变化
- 数据湖的主要优势是不同内容源的集中化
- 各个部门的用户可能遍布全球,可以灵活的访问数据
使用数据湖的风险如下:
- 一段时间后,数据湖可能会失去相关性和动力
- 数据湖的设计风险较大
- 非结构化数据可能导致无法掌控的混乱、不可用的数据、不同且复杂的工具、企业范围的写作、统一、一致和通用问题
- 增加了存储和计算的成本
- 无法从数据打交道的其他与人那里得到见解
- 数据湖最大的风险是安全和访问控制。有时,数据在没有任何监督的情况下放入湖中,某些些数据具有隐私和监管要求
# 总结
- 数据湖是可以存储大量结构化,半结构化和非结构化数据的存储库。
- 建立数据湖的主要目的是向数据科学家提供未完善的数据视图
- 统一操作层,处理层,蒸馏层和HDFS是数据湖架构的重要层
- 数据提取,数据存储,数据质量,数据审核,数据探索,数据发掘是数据湖架构的一些重要组成部分
- 数据湖的设计应由可用而非所需驱动
- 数据湖降低了长期拥有成本,并允许经济地存储文件
- 数据湖的最大风险是安全性和访问控制。有时,数据放入湖泊中而没有任何监督,某些数据可能具有隐私和监管要求